
Engineering
![]() 10 min read
10 min read
Artera’s AI/ML Architecture

AI/ML Architecture at Artera
The Artificial Intelligence and Machine Learning (AI/ML) world is iterating at an astonishing rate. New technologies and techniques have the potential for massive impact across an organization. They can increase both internal efficiency and, in Artera’s case, enable healthcare organizations to better reach their patients. It can help provide them with clearer, more relevant, more up-to-the-minute information.
AI/ML can’t just be dropped in and expected to be impactful. Model training and tuning, performance monitoring and validation, and low-latency software architecture are all required to bring it all together. This blog shares a basic architecture of Artera’s AI/ML model, the processes around training, validating, and deploying such models, and overall learnings from the AI/ML team.
AI/ML Definitions
It can be hard to distinguish some of the terminologies in the AI/ML world, so here I want to share our definitions to create consistency throughout the blog.
- Artificial Intelligence (AI): AI is a field of computer science focused on creating software that can mimic human capabilities. Ideally, it is capable of understanding broader context and offering deep analytic insights and efficient automations.
- Machine Learning (ML): ML is how AI is achieved. It’s the broader process and science of data curation, model selection, model training, validation, and monitoring. It is how the AI is “taught” to recognize patterns and provide insights.
- Generative AI: Generative AI refers to a class of models that can generate new content based on their training data. These are often open source models that are fine tuned with internal data to bias them towards the responses desired by the user. LLMs, or large language models, are a subset of Generative AI.
System Overview
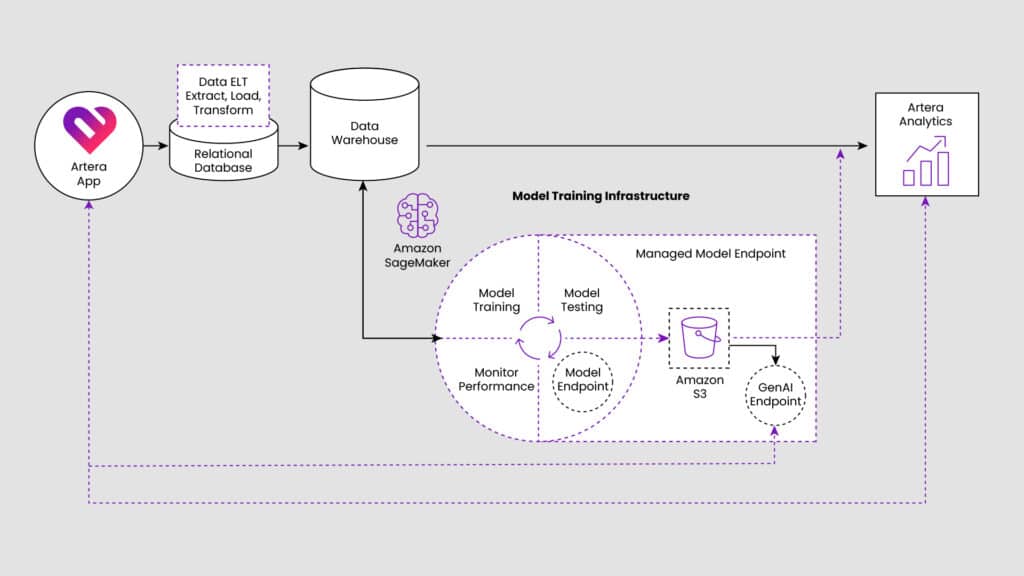
The basic architecture of Artera’s AI/ML program is fairly standard. This enables faster iteration, quick onboarding of new engineers, and easy maintenance. It’s focused heavily on AWS, offloading responsibility for downtime, again providing for faster iteration and a deeper focus on customer outcomes rather than time-consuming engineering excellence tasks. There is an emphasis on similar tools being used by all the ML Engineers so processes are repeatable and work is easily transferable.
Privacy and Security
Artera takes privacy and security very seriously. Only data from consenting customers is used in the process, and all of it is automatically scrubbed of any Personal Health Information (PHI) according to HIPAA standards. Artera carries the following privacy and security certifications:
- HITRUST
- SOC 2 Type II
- ISO-27001
- ISO-27701
- ISO-27017
- ISO-27018
AI/ML Model Training
Model training is the process of feeding data into a machine learning algorithm so it can “learn” the data you want it to learn. It involves careful selection and curation of input data and changing the parameters of the algorithm to optimize performance. Training classifiers, models that determine which “class” a given piece of data belongs to, provide an easy example. If millions of messages are received from patients per day, it may be important to know which ones are about billing so you can direct them to the appropriate person. In this case, the classes could be “billing” and “other”. Data selection would involve finding high-quality but varied examples of messages related to billing and all other questions so the algorithm can learn to differentiate between the two. Making sure the data is varied will help ensure the model can perform well on yet-unseen data, generalizing to what it has not seen in the carefully selected training set.
Training is done in Sagemaker Studio. Developers can iterate and test code on smaller, less expensive instances and then run more compute-heavy training jobs on much larger instances, only paying for the time the instance is being used. Interim data and model artifacts are stored in S3.
Training processes vary from model to model depending on the use case. Some models are built from the ground up and others are fine tuned versions of open source LLMs. The open source LLMs are pulled from either Huggingface or AWS Bedrock. Any Huggingface models are stored in S3 to avoid dependencies on their infrastructure.
AI/ML Model Validation
Model validation is the process of determining if a model performs well or not. It’s imperative that engineers understand how well it performs in the real world, not just in a tightly controlled environment.
The validation process is heavily dependent on the models application. We leverage anyone and everyone to help with reviewing model output, from product managers to UI/UX experts to ML Engineers.
For classification tasks, we create randomly sampled, subsets of data and hand them out to the people we’ve pulled into the task. Each person reviews the data after being given a clear understanding of the class definitions. Agreement across shared datapoints is then analyzed and, if agreement is high and the performance metrics are acceptable and not highly variable, then the model is shipped. Automated performance monitoring is then put in place, periodically running validated datasets in production against the production model to detect drift.
For generative AI models, we have a Streamlit UI set up with a simple process for adding new models. Product managers, UX designers, and others can then interact with the model using whatever process they see fit to validate the quality of the output.
Deployment
At Artera, we have three deployment methods that we use for different use cases: AWS Bedrock, Sagemaker Endpoints, and an internal ML-API. Every method is secured and protected and cannot be accessed over the internet. Data security is incredibly important in AI and healthcare, and Artera takes it seriously.
AWS Bedrock
AWS Bedrock models are used when well-prompted, off the shelf LLMs are desirable. We want to move fast, so evaluating if using something that’s already been built is an important part of our process. There’s no need to reinvent the wheel, and the models available through Bedrock are excellent. We currently use Anthropic’s Claude models through Bedrock to automatically summarize conversations between patients and providers.
Sagemaker Endpoints
Deployment to Sagemaker inference endpoints is standard when a model has been trained or tuned internally. Deployment is straightforward after training in Sagemaker Studio. The autoscaling functionality offered here is also key to both cost savings and low latency. We use this method for classifying patient messages as they come into the system.
Pipeline and Batch Transforms
There are some complex tasks that require larger pipelines and batch jobs, running on a schedule when all the necessary data is collected and available. These jobs write data into a table for further analysis and exposure as in-app features.
Internal ml-api
The ML/AI team also owns a Python Flask API deployed on Kubernetes. This exists for models that have a high amount of custom pre and postprocessing. This platform requires more engineering expertise than the others, but allows for very fast iteration and testing and has the benefit of being entirely internal. It provides incredible flexibility when that’s desired and can easily combine database calls/data aggregations with AI powered insights into single API calls, making for easy integration with the front end of the app. We use this method for predictive text and translation.
Learnings
The AI/ML program at Artera has been built quickly from the ground up over the last year. There are a few big takeaways from this.
- Be lean. Hire a few trusted, experienced engineers who know how to train, deploy, and monitor models independently.
- Be repeatable. Have a process that doesn’t require reinventing the wheel with each new project.
- Be willing to evolve. The field is constantly changing, especially over the last year. Be willing to make sudden turns.
- Be stable. Focus on deployment processes that require minimal engineer attention once they’re up and running.
- Be product driven. Don’t build a sports car when a reliable commuter will get the job done. There’s a temptation in the field to deploy the newest, shiniest technology, but that shouldn’t be the focus. The best technology is the one that solves the business problem.
Artera AI/ML will continue to change and grow well into the future. I look forward to re-visiting this blog again in a year when our nimble, efficient team of Machine Learning Engineers has gathered additional insights so we can continue to support seamless communication between providers and patients.
About Artera:
*Artera is a SaaS digital health leader redefining patient communications. Artera is trusted by 800+ healthcare systems and federal agencies to facilitate approximately 2.2 billion messages annually, reaching 100+ million patients. The Artera platform integrates across a healthcare organization’s tech stack, EHRs and third-party vendors to unify, simplify and orchestrate digital communications into the patient’s preferred channel (texting, email, IVR, and webchat), in 109+ languages. The Artera impact: more efficient staff, more profitable organizations and a more harmonious patient experience.*
Founded in 2015, Artera is based in Santa Barbara, California and has been named a Deloitte Technology Fast 500 company (2021, 2022, 2023), and ranked on the Inc. 5000 list of fastest-growing private companies for four consecutive years. Artera is a two-time Best in KLAS winner in Patient Outreach.
For more information, visit www.artera.io.
Artera’s blog posts and press releases are for informational purposes only and are not legal advice. Artera assumes no responsibility for the accuracy, completeness, or timeliness of blogs and non-legally required press releases. Claims for damages arising from decisions based on this release are expressly disclaimed, to the extent permitted by law.

Our Journey to a Scalable SSE Architecture
Today’s users expect a dynamic application experience, where text messages appear instantly and the real-time activities of colleagues are always…

Bridging the Analytics Gap: Why We Are Reimagining Our Client Data Experience
The Challenge: Embedded Analytics That Fall Short At Artera, we’ve consistently prioritized providing our clients with powerful data insights. Until…

Artera’s 2024 Year in Review
Looking back at 2024, the Innovation Organization (iO) had a fantastic year. Like most start-ups in 2024 we had our…