
Engineering
![]() 8 min read
8 min read
How we manage Kubernetes internals with full CI/CD

At Artera, we want to build a modern infrastructure stack for our applications, while still being as rock solid as possible. As a result we have chosen Kubernetes as our application platform of choice. Kubernetes is a very powerful tool however it also requires the right tooling to take advantage of that power. To make things easier we wanted to leverage modern CI/CD patterns that would allow us to ship changes to Kubernetes and its add-ons more quickly and safely.
Our migration to Kubernetes
Kubernetes is a very mature ecosystem that provides many tools to help you get going quickly. I think it is fair to argue that Kubernetes now falls in the Boring Technology category. Early in 2024 we migrated all of our applications from AWS Elastic Container Service (ECS) to AWS Elastic Kubernetes Service (EKS) managed Kubernetes clusters. Part of setting up an EKS cluster involves installing all of the add-ons that work in lockstep with our applications. These add-ons can include anything from load balancers, a service mesh, or monitoring components. These components are critical for building secure EKS based application deployments. Initially we had several separate patterns for installing our add-ons but we quickly realized that we would need to consolidate these before managing them became too difficult.
⚠️NOTE: EKS has its own concept of add-ons which includes a select few Kubernetes resources that are managed directly through EKS (things such as the VPC CNI and the EBS Controller). We have chosen to implement these alongside our EKS infrastructure code instead to make them easier to manage since they are generally upgraded along with EKS version upgrades.
Choosing GitHub Actions
The DevOps team was responsible for writing application deployment pipelines in GitHub Actions initially with ECS and then finally with EKS. During our analysis of options we wondered if this code and knowledge could be used elsewhere. We reviewed this code and realized that we could easily reuse it for any Kubernetes based deployment scenario. We decided to build on that code and implement a full CI/CD pattern with our Kubernetes infrastructure. We were able to reuse almost all of the code we used to deploy our applications, which allowed us to move and deliver quickly.
What if some changes only apply to certain environments?
We have 2 concepts to handle scenarios like this; environment ignore and environment override. With environment ignore (envignore for short), we can simply place a file in the directory of the add-on specifying which environments that this add-on should “ignore” or not install to. For the environment override, we provide an additional structure to override certain values and variables with ones that are specific to a certain environment. For example, if you needed a different value in Stage, perhaps a lower amount of reserved memory or CPU based on traffic, you can utilize an environment override file to specify values only for Stage. Our GHA pipeline then merges these values in order of precedence, with the environment override taking precedence in Stage.

A sample add-on configuration. Updating the version is as simple as bumping the version in this file!
How does it all come together?
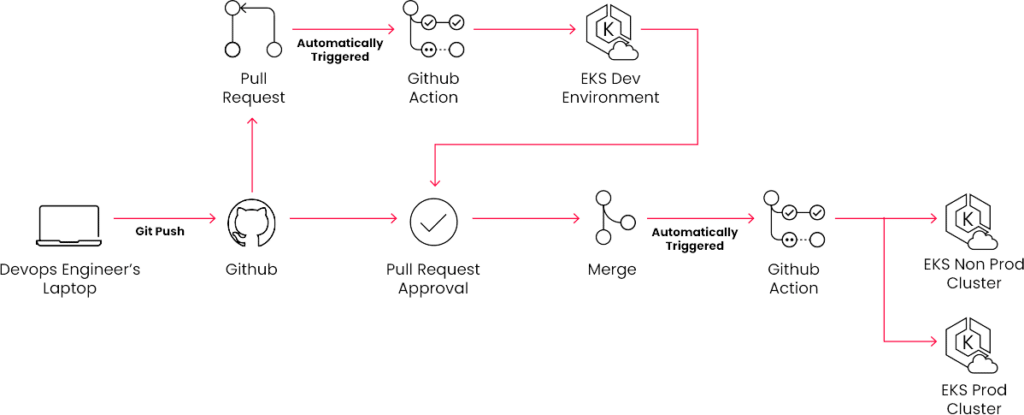
For any changes to an add-on or net new add-on installs we start by opening a Pull Request on GitHub. The GitHub Actions Pipeline triggers an automatic deploy to a Kubernetes cluster development environment. That deployment can then be validated through automated or manual testing. Once testing is validated we then have code review and approval. Once the pull request is merged, another GitHub Actions Pipeline is triggered which does a staggered rollout of the change to all further Kubernetes clusters. These pipelines together enable full Continuous Integration/Continuous Delivery of our Kubernetes add-ons.
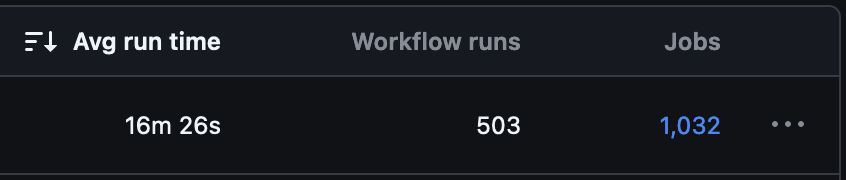
How long does it take to apply changes to every Kubernetes environment? We’re averaging under 17 mins since go live!
Summary
With this new delivery model in place, we have been able to scale our Kubernetes footprint quickly and safely deploy changes without causing any SEV-1 incidents. DevOps engineers also do not need to worry about running scripts locally and having to keep track of changes across environments. All they need to focus on is creating/updating a few files and the changes can be deployed and tested in a matter of minutes. We now have the tooling in place to continue to grow and scale at a fast pace.
What’s Next?
We are always making changes to improve our pipelines and make them even faster and more efficient. An example that we are thinking about in the future is utilizing concepts like Dependabot to automatically submit pull requests to update our add-ons to their latest versions, reducing that amount of manual work required on our part. As we continue to evolve our application deployment model, we are reviewing additional tooling to add to our Kubernetes deployment pipelines to enhance them even further.
Lessons Learned
- Reusable code is your friend
Being able to reuse our existing app deployment GitHub Actions code allowed us to design a solution quickly that we knew was proven and battle tested. This has also allowed us to ship enhancements made in our add-ons pipelines back to our applications pipelines.
- Keep things as consistent as possible
As a DevOps team supporting many other teams, we want to avoid reinventing the wheel unless absolutely necessary. For this project, that meant reducing the number of deployment methods we build and support. This means that we can help app teams deploy code with pipelines that we know are proven because we use them ourselves.
- Keep things as simple as possible
Simple is always better than complex. Our pipeline code and configuration files are designed to be simple and intuitive to make it easier to maintain our Kubernetes add-ons
- Keep extensibility in mind (but don’t design for it)
The application deployment code that we re-used for our add-ons deployments wasn’t originally intended for that purpose, but it had been designed in a way that it made perfect sense for it to be re-used. For all of our new pipeline code, we are always thinking about different ways that it could be used for other purposes without specifically designing it that way.
About Artera:
*Artera is a SaaS digital health leader redefining patient communications. Artera is trusted by 800+ healthcare systems and federal agencies to facilitate approximately 2.2 billion messages annually, reaching 100+ million patients. The Artera platform integrates across a healthcare organization’s tech stack, EHRs and third-party vendors to unify, simplify and orchestrate digital communications into the patient’s preferred channel (texting, email, IVR, and webchat), in 109+ languages. The Artera impact: more efficient staff, more profitable organizations and a more harmonious patient experience.*
Founded in 2015, Artera is based in Santa Barbara, California and has been named a Deloitte Technology Fast 500 company (2021, 2022, 2023), and ranked on the Inc. 5000 list of fastest-growing private companies for four consecutive years. Artera is a two-time Best in KLAS winner in Patient Outreach.
For more information, visit www.artera.io.
Artera’s blog posts and press releases are for informational purposes only and are not legal advice. Artera assumes no responsibility for the accuracy, completeness, or timeliness of blogs and non-legally required press releases. Claims for damages arising from decisions based on this release are expressly disclaimed, to the extent permitted by law.


Our Journey to a Scalable SSE Architecture
Today’s users expect a dynamic application experience, where text messages appear instantly and the real-time activities of colleagues are always…

Bridging the Analytics Gap: Why We Are Reimagining Our Client Data Experience
The Challenge: Embedded Analytics That Fall Short At Artera, we’ve consistently prioritized providing our clients with powerful data insights. Until…

Artera’s 2024 Year in Review
Looking back at 2024, the Innovation Organization (iO) had a fantastic year. Like most start-ups in 2024 we had our…